Part 2 - Kick-starting your journey in Data Engineering
The Bigger picture
Hello everyone, welcome back. So if you are joining back from my last blog, you must be pretty excited to know about the problems thrown to us by big data. If you have not yet gone through the last blog, I highly recommend you to do so. But nevertheless, you can carry on.
Cool, so now we know storing and serving large amounts of data is a problem. But there is a larger problem attached to it. Let me explain it to you.
Suppose your client is a billion-dollar company, and they capture their user’s location data (ahem..). And they want to create an attractive dashboard that shows the places the users have visited over the past month. So for this, they would require you to fetch every user’s data for the past month and run a job over it to generate the final output. This approach would work for small sized data but will definitely fail when the data size grows exponentially.
Let’s try to figure out the exact pitfall in the above mentioned approach. What we are basically doing is bringing in data from a database into our application server and then running a process over it. Suppose there are 1 million users, each having an average data volume of about 50 MB. Now you are looking at 50 TB of data transfer from your database to your application server and processing 1 million users’ jobs. Needless to say, your server is going to be roasted. Thus we can conclude that bringing data into your main application system has both network and performance implications. Many large tech giants faced these issues in the early 2000s and some great engineers came together to create a paradigm shift in data processing.
You don’t bring data to your job, you take your job to the data.

Tada… the above statement literally changed the world’s view on data processing.
So with this, we understood it’s better to take the computation to the place where the data resides. This gives us two main advantages, firstly - we are not wasting time on transferring data, and secondly - the computations can be run in parallel over multiple partitions of data if the computations support it. Ehhh, yes it may be difficult to understand. So another not so typical analogy coming in:
Suppose you are an invigilator in an examination. Almost 100 students are seated in the examination hall and you have the responsibility of getting signatures of all candidates on the attendance sheet. Generally, that would mean you are going to each and every student and marking them one at a time. Problems? It’s time-consuming, and you are lazy.
So let’s try to use the analogy we learnt earlier. Instead of you carrying out the task of going to every student’s desk to take their signature, you can instead pass the attendance sheet to them. This means you pass on the attendance sheet to the student seated first in every column. Each student passes it on to the student seated behind them. Eventually the backbenchers come back and submit the sheet back to you. Advantages? Their speed is more because in multiple columns we have multiple students signing at the same time. More the columns, more the speed. Also, you get to sit and relax!
Here goes in a diagram to explain the same, don’t worry if you find this a bit intimidating. We will cover it in the upcoming blogs.
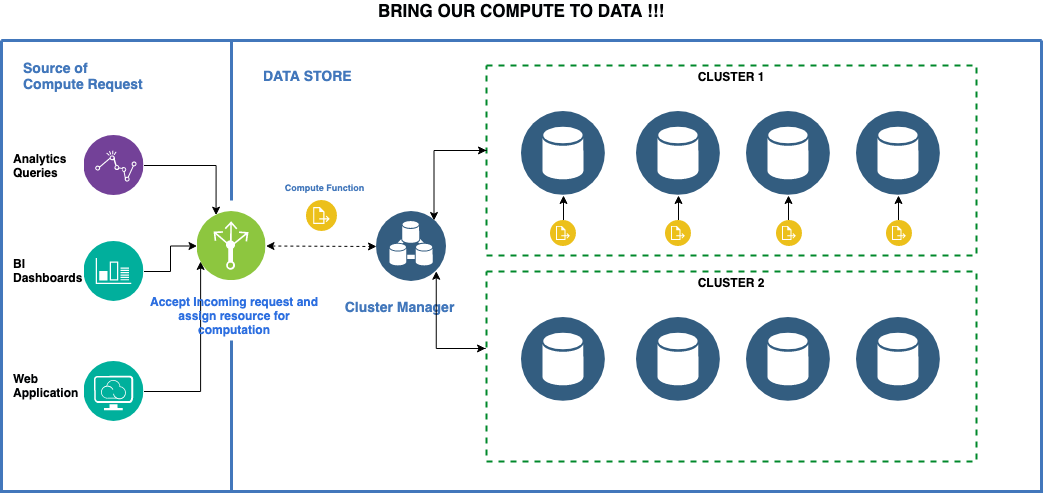
I hope it might be clear now, that it’s important to transfer the computation to a place where data resides. So enough concepts, when do we talk about tech? When do we see some actual code?
We will, we will. Now that you have a more clear understanding of what we are trying to solve and how it can be achieved, we will now look at the tools and frameworks we have at present to handle the above problems.